
Forge CLI
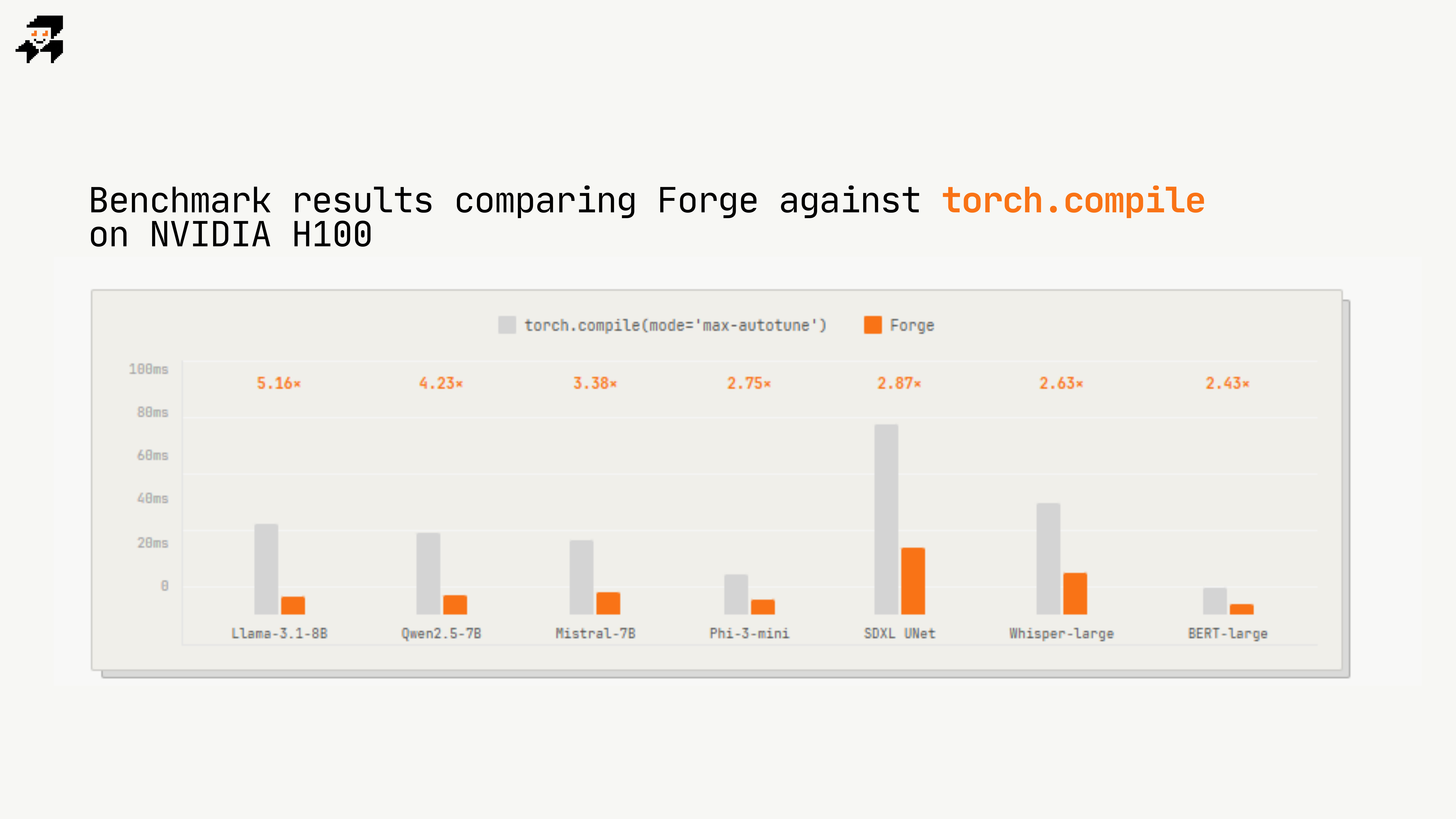
Forge generates optimized GPU kernels from any PyTorch or HuggingFace model. 32 parallel Coder+Judge agents compete to find the fastest CUDA/Triton implementation. Up to 5× faster than torch.compile(mode='max-autotune') with 97.6% correctness. Enter HuggingFace model ID, get optimized kernels for every layer. Powered by optimized NVIDIA Nemotron 3 Nano 30B at 250k tokens/sec. "Full refund if we don't beat torch.compile"


More in Developer Libraries

SuperX
SuperX is an all-in-one growth toolkit for 𝕏. Get daily inspiration based on viral posts in your niche, trend-based research, and fast rewrites in your voice. Schedule posts at the best time, engage with the right accounts to get discovered, and track what works with built-in analytics.

Surgeflow
See the plan. Approve it. Watch it execute. SurgeFlow turns browser chaos into transparent automation across multiple tabs. Research, shopping, job applications—all with one command. Works in your browser—no need to download or install a new one.

Fluently Accent Guru
Are you a non-native English speaker? Check out our free English accent test. Fluently Accent Guru listens to your voice and guesses your accent in just 30 seconds. It’s fast, free, and surprisingly accurate. Try it to improve your English speaking skills!

Lovon AI Therapy
AI therapy you can actually talk to. Just speak naturally and get support anytime you need it.