
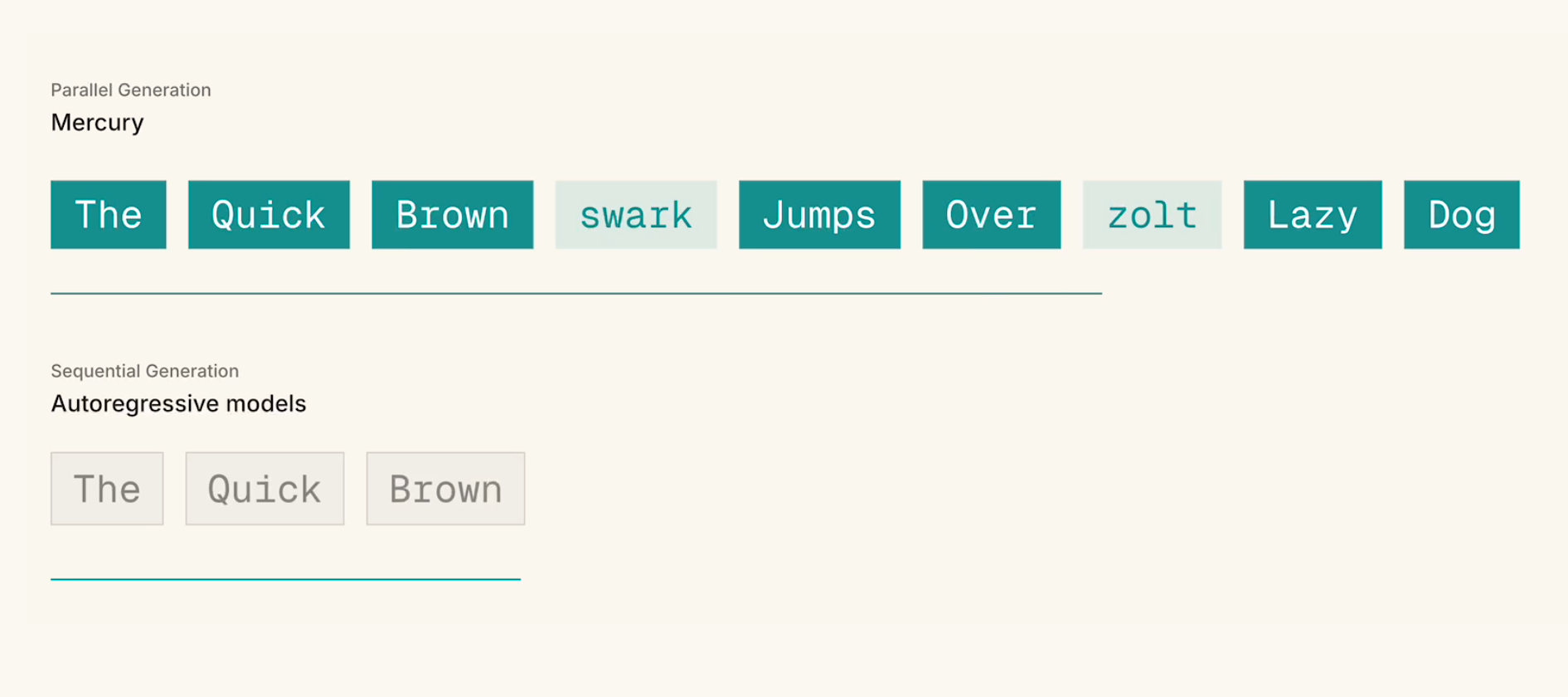
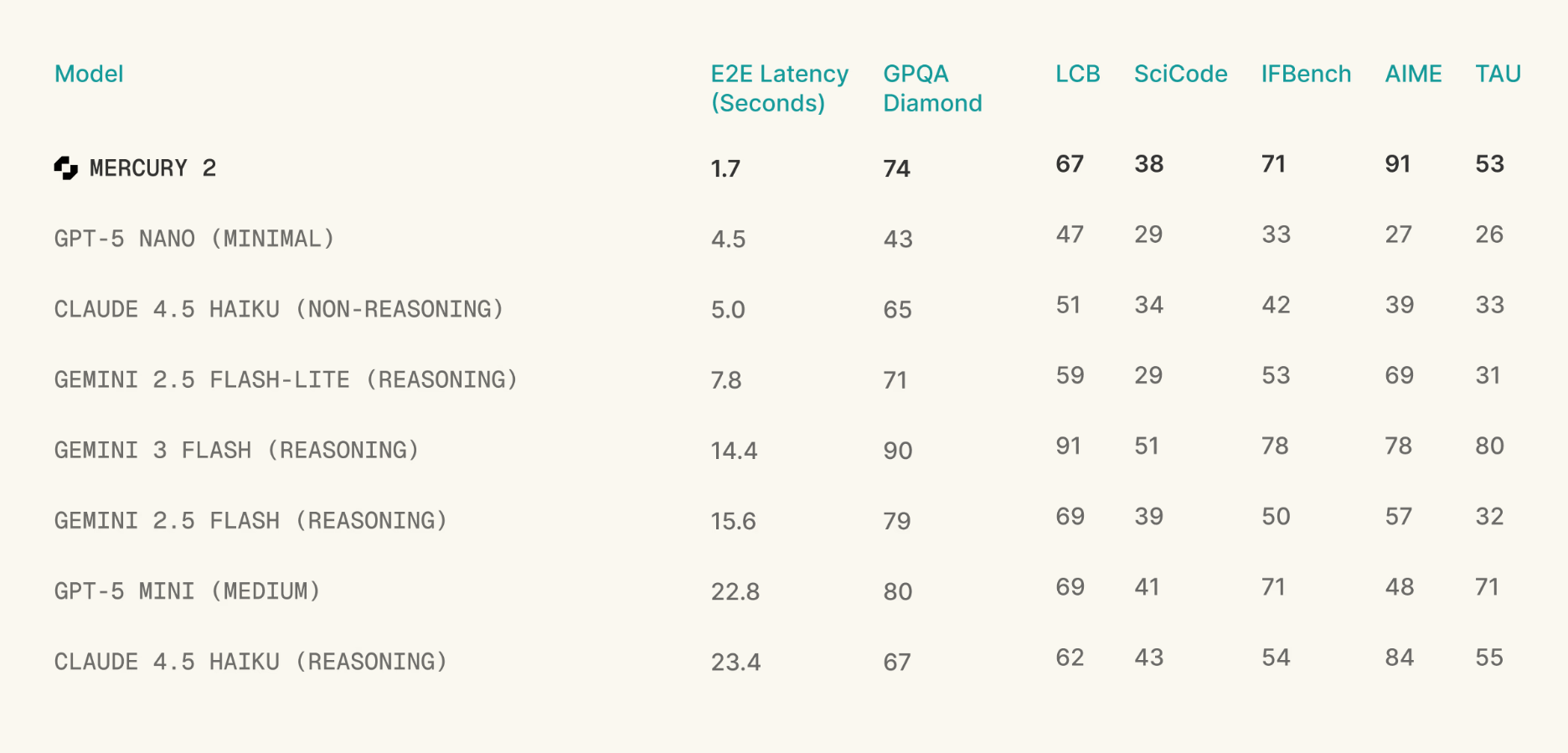
Mercury 2
Mercury 2 ditches sequential decoding for parallel refinement. As the first reasoning diffusion LLM, it generates tokens simultaneously to hit 1,000+ tokens/sec. This delivers reasoning-grade quality inside tight latency budgets for your agentic loops.


More in AI & LLM Tools

Cowork
Cowork turns Claude into a real coworker. Give it access to a folder on your computer and assign tasks instead of chatting. Claude can read, edit, and create files, plan its work, and execute tasks end-to-end while keeping you in control. Less back-and-forth, more work done.

CyberCut AI
CyberCut AI helps creators and teams produce viral videos fast. Auto-slice long footage into social-ready clips, generate marketing videos, add high-precision subtitles, edit by text, access an AI asset library, try virtual model try-ons, and use a full AI toolkit.

PlanEat AI
Most apps drown you in recipes; chatbots drown you in text. PlanEat AI turns your health data and food rules into one realistic weekly plan and a grouped shopping list, so you don’t have to prompt, copy-paste or build spreadsheets by hand. Set it up once and try the weekly flow with a free trial.

PostSyncer
The most powerful tool to manage all your social accounts at scale. Create, schedule, and reply across 10+ platforms. Get inspiration from the viral content library, generate media with AI (Sora, Veo & more), connect unlimited accounts and manage clients in dedicated workspaces.